

IoT device management protocols: LwM2M, OMA-DM and TR-069
February 5, 2019
What can Augmented Reality do for you?
March 3, 2019
Big Data, fuel of the AI
Artificial intelligence, promises to be one of the technological revolutions of this century, not only because of its future possibilities, but also because of its present use. However, its explosion is due in large part to the data revolution, which revalued and became the "new oil of society". Creating specialized sectors in its analysis and processing, from which emerge solutions such as the monitoring of the industry, capable of giving them value and integrating this information into everyday decision-making.
Digitization brings with it a huge volume of information, of different form and type that arrives continuously and updated, supported by the IT sector. This is produced by people and every day more by electronic devices together with the paradigm of the Internet of Things (IoT), resulting in what we know today as "Big Data". These data help Artificial Intelligence devices learn how human beings think and feel. They accelerate their learning curve and also allow the automation of data analysis.
To store this digital data we traditionally develop database models, whose purpose is to structure the information in a way that is as accessible as possible. Although there are many models, we can highlight two: Relational and non-relational.
Digitization brings with it a huge volume of information, of different form and type that arrives continuously and updated, supported by the IT sector. This is produced by people and every day more by electronic devices together with the paradigm of the Internet of Things (IoT), resulting in what we know today as "Big Data". These data help Artificial Intelligence devices learn how human beings think and feel. They accelerate their learning curve and also allow the automation of data analysis.
To store this digital data we traditionally develop database models, whose purpose is to structure the information in a way that is as accessible as possible. Although there are many models, we can highlight two: Relational and non-relational.
Relational Model
It is based on the ACID principle (atomicity, consistency, isolation [insolated] and durability), its organization is based on tables and could be compared to the structure used by the popular office tool EXCEL. Its name arises from the ability of this model to describe relationships between tables, which allows structuring the data and its connections.
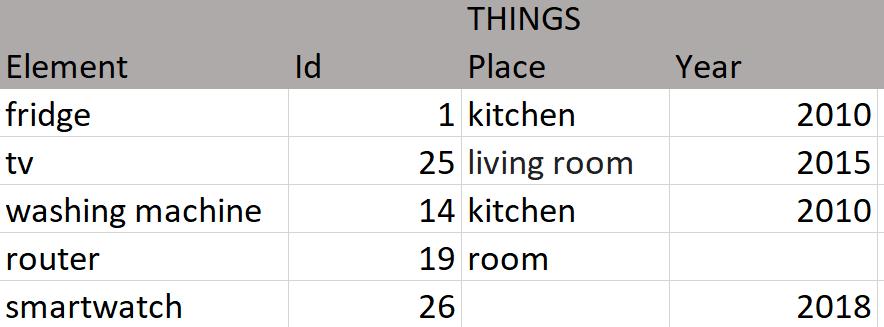
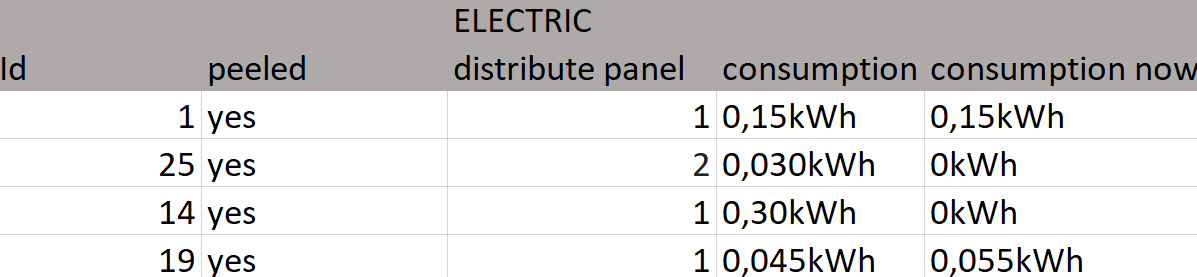
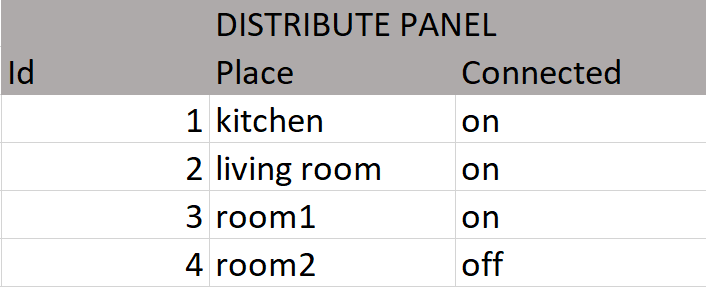
Let's see these example tables that are a possible solution to the representation of the data of a house with a monitoring system, its objective is to allow to measure the electrical consumption of certain household elements. The tables perfectly describe most relationships. However there are descriptions that do not fit the reality, it seems difficult to define the location of a smartwatch.
Since the characteristics are not necessarily common to all entries in the table, they cause gaps. Another case that does not adapt correctly is the year of manufacture of the router, it is a difficult fact to know a priori being the team of our network operator. From these cases we can deduce that the descriptions are inefficient for characteristics that are not common to the elements of a table, being a model with little flexibility and with low adaptability.
Since the characteristics are not necessarily common to all entries in the table, they cause gaps. Another case that does not adapt correctly is the year of manufacture of the router, it is a difficult fact to know a priori being the team of our network operator. From these cases we can deduce that the descriptions are inefficient for characteristics that are not common to the elements of a table, being a model with little flexibility and with low adaptability.
Non-relational Model
Unlike tables, this model describes elements, and with it all its characteristics, for this we will use JSON, a light text format for data exchange. It should be noted that this model is portable to a table format, it is only a way to visualize the data, each row representing a JSON or any other type of adaptation that occurs to us and that fits the data to be represented.

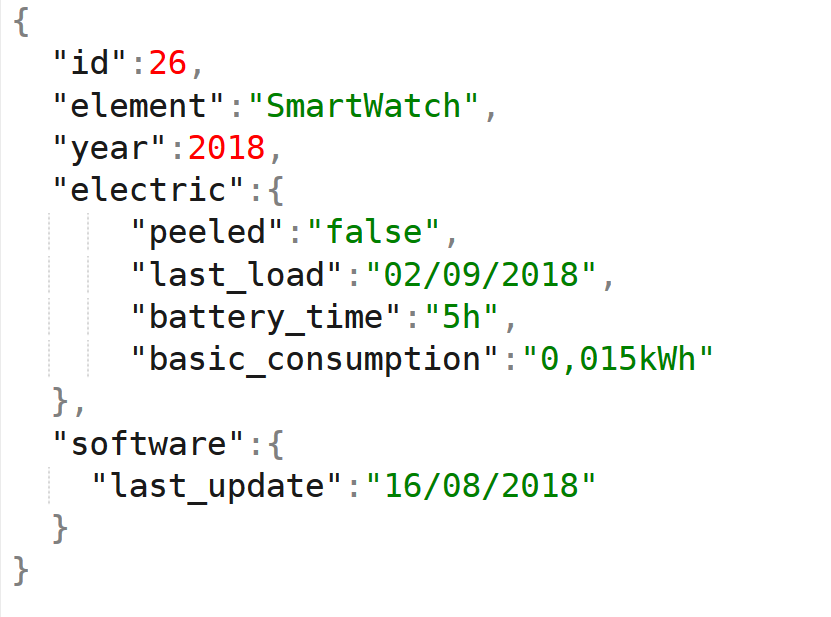
We see in this case that we focus the problem on describing each element individually, and adjusting to its characteristics, creating polymorphic elements. In this way we can adapt to each element and include unique elements, such as the latest update of the smartwatch or the temperature of the fridge, resulting more efficient. All the characteristics of an element are stored in the same place and the uncommon fields do not occupy a space or consume memory in the queries.
We can also think that we do not know the future elements that this home will have, what characteristics it will have or that we will want to monitor them, before so many uncertainties this model raises advantages beyond the simplicity of its description.
In the example described, the use of a relational model may seem appropriate, given that the number of elements in a house is not, a priori, excessive and the small discrepancies that may arise, to make a good design of the database, they are not relevant when analyzing the performance of the system. This does not happen when the amount of data is huge, here each operation produces a high cost of performance and its design can be a real problem, if it is intended to remain in time and adapt to changes.
It seems that from the point of view of the data growth, the uncertainties posed by the data of the future and its variability, the vertical scaling (scale-up) offered by the relational databases, in principle, does not seem a good solution to the horizontal scaling (scale-out) of the distributed environments of the main NoSQL databases
We can also think that we do not know the future elements that this home will have, what characteristics it will have or that we will want to monitor them, before so many uncertainties this model raises advantages beyond the simplicity of its description.
In the example described, the use of a relational model may seem appropriate, given that the number of elements in a house is not, a priori, excessive and the small discrepancies that may arise, to make a good design of the database, they are not relevant when analyzing the performance of the system. This does not happen when the amount of data is huge, here each operation produces a high cost of performance and its design can be a real problem, if it is intended to remain in time and adapt to changes.
It seems that from the point of view of the data growth, the uncertainties posed by the data of the future and its variability, the vertical scaling (scale-up) offered by the relational databases, in principle, does not seem a good solution to the horizontal scaling (scale-out) of the distributed environments of the main NoSQL databases
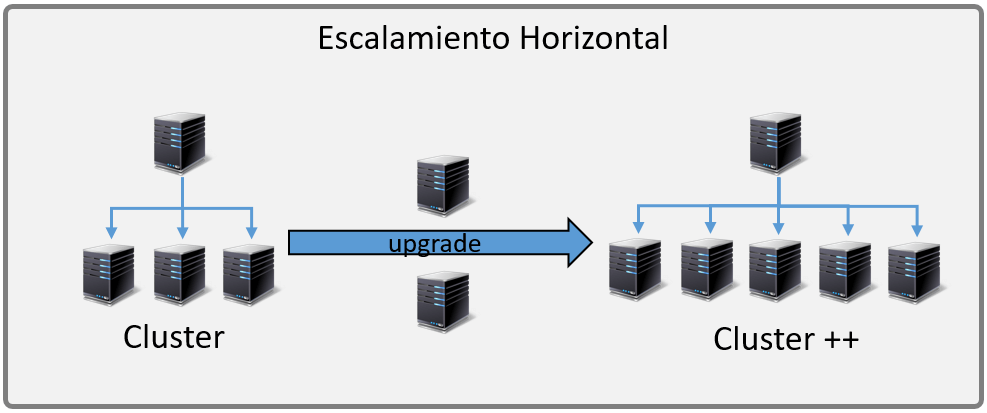
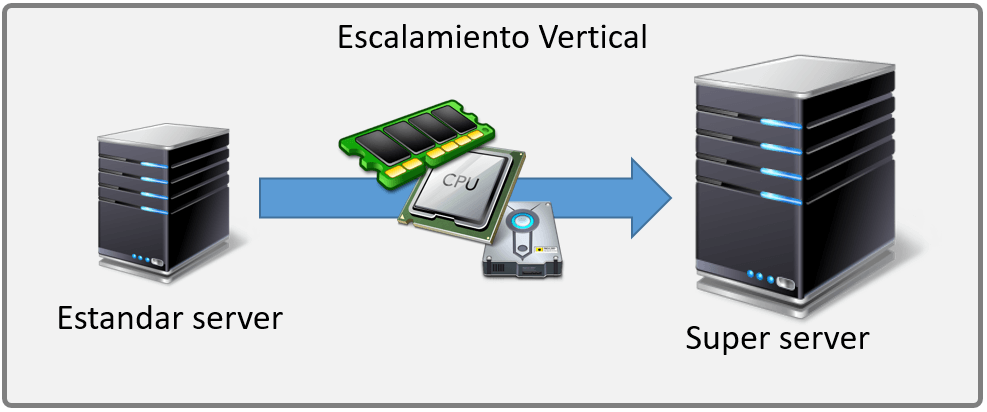
IA and its data
All these "problems" involve the awakening of the AI and the possibility of its "democratization" reaching all sectors, improving services and enhancing the efficiency of systems being more precise.
The current availability of data, its quantity and current computing capabilities allow fields of study such as "machine learning" to become a very interesting option for many business sectors, not only for its business model but also to optimize its own production systems.
Returning to the example of monitoring it seems interesting, for any sector, to have not only the available data, but to make them useful, to have the perspective that gives a vision of your business in real time, that provides total control, improving decision making.
It is exciting that this perspective thanks to the AI reaches beyond the current moment, being able to predict, starting from the data of your company, what will happen even before this happens: alerts and their prevention of failures; detailed control of consumption and optimization of them, these optimizations can be in real time and without human control, etc.
Big Data and its solutions are the fuel of the AI, therefore knowing how we can adapt and structure the information so that it is developed and can come to add value to the data of the companies, is one of the fields in which Muutech is making efforts to provide better solutions to all sectors through this technology.

DEVELOPMENT AND DIGITALIZATION MANAGER
Expert in industrial monitoring and IT monitoring.
We help companies fight against stoppages and degradation of IT systems and industrial processes.
Transform your monitoring data into valuable information, anytime, anywhere
Improve the efficiency and decision-making of your company!
Subscribe to our Newsletter



{kind=link}
{kind=link}