

Protocolos de gestión de dispositivos IoT: LwM2M, OMA-DM y TR-069
febrero 5, 2019
¿Qué puede hacer por ti la Realidad Aumentada?
marzo 3, 2019
Big Data, combustible de la IA
La inteligencia artificial, promete ser una de las revoluciones tecnológicas de este siglo, no solo por sus posibilidades futuras, sino también por su uso presente. Sin embargo su explosión se debe en gran parte a la revolución de los datos, que los revalorizó y convirtió en el “nuevo petróleo de la sociedad”. Creando sectores especializados en su análisis y procesamiento, de los cuales emergen soluciones como la monitorización de la industria, capaces de darles valor y que integran esta información en la toma de decisiones cotidianas.
La digitalización trae consigo un enorme volumen de información, de distinta forma y tipo que llega de manera continua y actualizada, apoyada por el sector IT. Esta es producida por personas y cada día más por dispositivos electrónicos junto con el paradigma del Internet de las Cosas (IoT), dando como resultado lo que hoy conocemos como “Big Data”. Estos datos ayudan a que los dispositivos de Inteligencia Artificial aprendan cómo piensan y sienten los seres humanos. Aceleran su curva de aprendizaje y también permiten la automatización de análisis de datos.
Para almacenar estos datos digitales tradicionalmente desarrollamos modelos de bases de datos, cuya finalidad es estructurar la información de manera que sea lo más accesible posible. Aunque existen muchos modelos, podemos destacar dos: Relacionales y no Relacionales.
La digitalización trae consigo un enorme volumen de información, de distinta forma y tipo que llega de manera continua y actualizada, apoyada por el sector IT. Esta es producida por personas y cada día más por dispositivos electrónicos junto con el paradigma del Internet de las Cosas (IoT), dando como resultado lo que hoy conocemos como “Big Data”. Estos datos ayudan a que los dispositivos de Inteligencia Artificial aprendan cómo piensan y sienten los seres humanos. Aceleran su curva de aprendizaje y también permiten la automatización de análisis de datos.
Para almacenar estos datos digitales tradicionalmente desarrollamos modelos de bases de datos, cuya finalidad es estructurar la información de manera que sea lo más accesible posible. Aunque existen muchos modelos, podemos destacar dos: Relacionales y no Relacionales.
Modelo Relacional
Se basa en el principio ACID (atomicidad, consistencia, aislamiento[insolated] y durabilidad), su organización está basada en tablas y podría compararse a la estructura usada por la popular herramienta ofimática EXCEL. Su nombre surge de la capacidad de este modelo para describir relaciones entre las tablas lo que permite estructurar los datos y sus conexiones.



Veamos estas tablas ejemplo que son una posible solución a la representación de los datos de una casa con un sistema de monitorización, su objetivo es permitir medir el consumo eléctrico de ciertos elementos del hogar. Las tablas describen perfectamente la mayoría de relaciones. Sin embargo existen descripciones que no se ajustan a la realidad, parece difícil definir la ubicación de un smartwatch.
Dado que las características no necesariamente son comunes a todas las entradas de la tabla, estas provocan vacíos. Otro caso que no se adapta correctamente es el año de fabricación del router, resulta un dato difícil conocer a priori siendo el equipo de nuestro operador de red. De estos casos podemos deducir que las descripciones resultan ineficientes para características que no son comunes a los elementos de una tabla, siendo un modelo poco flexible y con baja adaptabilidad.
Dado que las características no necesariamente son comunes a todas las entradas de la tabla, estas provocan vacíos. Otro caso que no se adapta correctamente es el año de fabricación del router, resulta un dato difícil conocer a priori siendo el equipo de nuestro operador de red. De estos casos podemos deducir que las descripciones resultan ineficientes para características que no son comunes a los elementos de una tabla, siendo un modelo poco flexible y con baja adaptabilidad.
Modelo No Relacional
A diferencia de las tablas este modelo describe elementos, y con él todas sus características, para ello utilizaremos JSON, un formato de texto ligero para el intercambio de datos. Cabe destacar que este modelo es portable a un formato de tablas, se trata únicamente de una manera de visualizar los datos, pudiendo representar cada fila un JSON o cualquier otro tipo de adaptación que se nos ocurra y que se ajuste a los datos a representar.


Vemos en este caso que centramos el problema en describir cada elemento de manera individual, y ajustándonos a sus características, creando elementos polimórficos. De esta manera podemos adaptarnos a cada elemento e incluir propiedades únicos, como la última actualización del smartwatch o la temperatura de la nevera, resultando más eficiente. Todas las características de un elemento están almacenadas en el mismo lugar y los campos no comunes no ocupan un espacio ni cosumen memoria en las consultas.
Podemos además pensar que desconocemos los elementos futuros que tendrá este hogar, que características tendrán o que querremos monitorizar de los mismos, ante tantas incertidumbres este modelo plantea ventajas más allá de la simpleza en su descripción.
En el ejemplo descrito puede que el uso de un modelo relacional parezca adecuado, dado que el número de elementos de una casa no resulta, a priori, excesivo y las pequeñas discrepancias que puedan surgir, de hacer un buen diseño de la base de datos, no son relevantes a la hora de analizar el rendimiento del sistema. Esto no ocurre así cuando la cantidad de datos es enorme, aquí cada operación produce un alto coste de rendimiento y su diseño puede resultar un verdadero problema, si se pretende que se mantenga en el tiempo y adapte a los cambios.
Desde el punto de vista del crecimiento de los datos, además de las incertidumbres que plantean los datos del futuro y su variabilidad, el escalado vertical (scale-up) que ofrecen las bases de datos relacionales, en principio, no parece una buena solución respecto al escalado horizontal (scale-out) de los entornos distribuidos de las principales bases de datos NoSQL.
Podemos además pensar que desconocemos los elementos futuros que tendrá este hogar, que características tendrán o que querremos monitorizar de los mismos, ante tantas incertidumbres este modelo plantea ventajas más allá de la simpleza en su descripción.
En el ejemplo descrito puede que el uso de un modelo relacional parezca adecuado, dado que el número de elementos de una casa no resulta, a priori, excesivo y las pequeñas discrepancias que puedan surgir, de hacer un buen diseño de la base de datos, no son relevantes a la hora de analizar el rendimiento del sistema. Esto no ocurre así cuando la cantidad de datos es enorme, aquí cada operación produce un alto coste de rendimiento y su diseño puede resultar un verdadero problema, si se pretende que se mantenga en el tiempo y adapte a los cambios.
Desde el punto de vista del crecimiento de los datos, además de las incertidumbres que plantean los datos del futuro y su variabilidad, el escalado vertical (scale-up) que ofrecen las bases de datos relacionales, en principio, no parece una buena solución respecto al escalado horizontal (scale-out) de los entornos distribuidos de las principales bases de datos NoSQL.
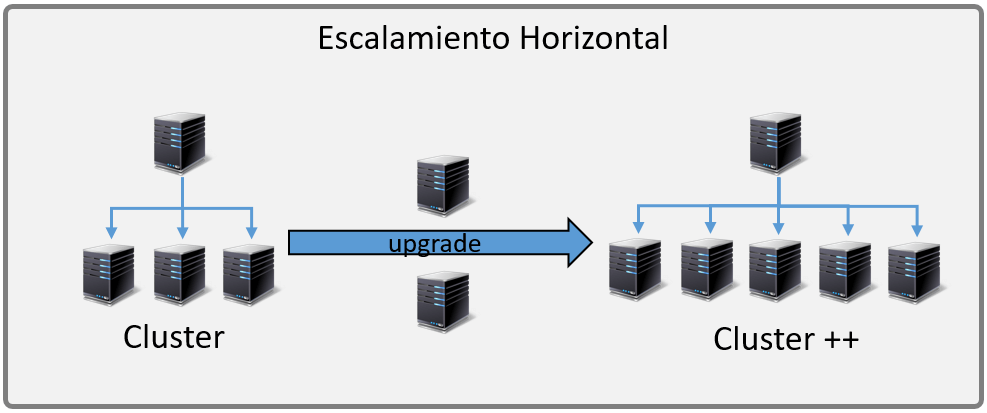
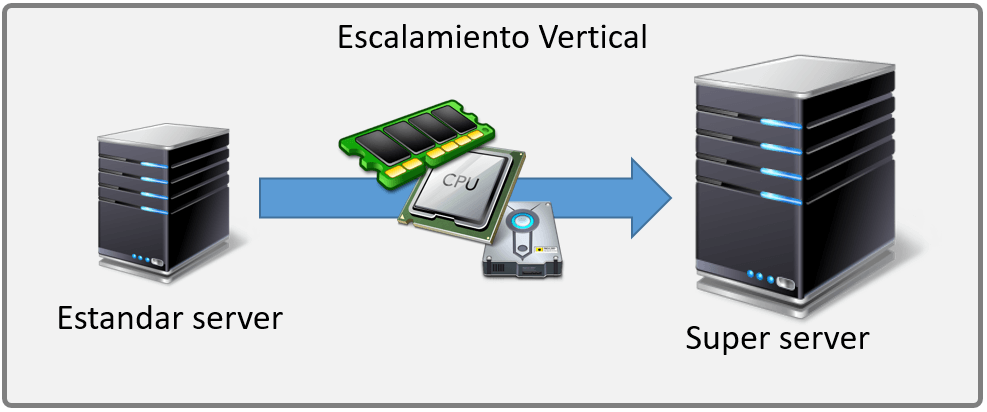
IA y sus datos
Todos estos “problemas” suponen el despertar de la IA y la posibilidad de su “democratización” llegando a todos los sectores, mejorando servicios y potenciando la eficiencia de sistemas siendo más precisos.
La actual disponibilidad de los datos, su cantidad y las capacidades de computo actuales permiten que campos de estudio como el “machine learning” se convierta en una opción muy interesante para muchos sectores empresariales, no solo para su modelo de negocio sino también para optimizar sus propios sistemas de producción.
Retomando el ejemplo de la monitorización parece interesante, para cualquier sector, tener no solo los datos disponibles, sino hacerlos útiles, tener la perspectiva que da una visión de su negocio en tiempo real, que dote de un control total mejorando la toma de decisiones.
Es ilusionante que esta perspectiva gracias a la IA llegue más allá del momento actual, pudiendo esta predecir, partiendo de los datos de su empresa, que sucederá incluso antes de que esto ocurra: alertas y su prevención de fallos; control detallado de consumos y optimizaciones de los mismos, pudiendo ser estas optimizaciones en tiempo real y sin el control humano, etc.
Big Data y sus soluciones son el combustible de la IA, por ello conocer cómo podemos adaptar y estructurar la información para que esta se desarrolle y pueda llegar a aportar valor a los datos de las empresas, es uno de los campos en los que Muutech está haciendo esfuerzos en poder dotar de mejores soluciones a todos los sectores a través de esta tecnología.

MANAGER DE DESARROLLO Y DIGITALIZACIÓN
Experto en monitorización industrial y monitorización IT.
Ayudamos a empresas a luchar contra paradas y degradaciones de sistemas IT y procesos industriales.
Transforma tus datos de monitorización en valiosa información, en cualquier momento y desde cualquier lugar
¡Mejora la toma de decisiones y la eficiencia de tu empresa!
Suscríbete a nuestra Newsletter



{kind=link}
{kind=link}