

The dark side of do-it-yourself
February 1, 2020
Monitoring, an ally in times of war
March 22, 2020
Management and classification of stops and microstops
Production stops are a burden on any factory. Not only because of the intrinsic lack of production, but also because of the fame it brings. A reputation of someone with problems and who does not meet orders on time. This is obviously not pleasant for anyone and is something to be avoided at all costs.
As we know, once we get a negative reputation, it is very difficult to eliminate. Therefore, it is best to tackle the problems as soon as possible. There are two ways to do this: either avoid the problems before they arise or solve them as quickly as possible and with little impact on production.
Although the first case is largely improvable thanks to monitoring, it is not the aim of today's blog. Since it is not all-powerful and not all breakdowns are completely predictable, today we are going to focus on the second case and see the different possibilities offered by a quick classification and management of problems, as well as a good representation of them.
One day, the factory owner wants to see how the factory works. Navigating through the data offered by the monitoring, he discovers that there were several production stops, but when he wants to go and see the reason why they occurred, he can't find it anywhere, because in his monitoring data the following comes up:
As we know, once we get a negative reputation, it is very difficult to eliminate. Therefore, it is best to tackle the problems as soon as possible. There are two ways to do this: either avoid the problems before they arise or solve them as quickly as possible and with little impact on production.
Although the first case is largely improvable thanks to monitoring, it is not the aim of today's blog. Since it is not all-powerful and not all breakdowns are completely predictable, today we are going to focus on the second case and see the different possibilities offered by a quick classification and management of problems, as well as a good representation of them.
Importance of classification
Let's take the case of a factory, in which all the machines are monitored. One day, there is a breakdown, which is quickly rectified by the employees, so it doesn't go any further. Another day, there is another production stop, this time due to a lack of stock. This time it is also solved quickly as material arrives quickly from the nearby warehouse. And so it continues with its routine.One day, the factory owner wants to see how the factory works. Navigating through the data offered by the monitoring, he discovers that there were several production stops, but when he wants to go and see the reason why they occurred, he can't find it anywhere, because in his monitoring data the following comes up:

Then you have two options, either go to the monitoring of those dates to see the reason for the stop or call the factory manager and tell him what the reasons were. And after that, you can modify the list of stops to classify these errors. Once these errors have been classified, the monitoring data will show the following:

As we can easily observe, both tasks performed by the owner are inefficient, since they involve a time lag between contacting someone who can help us or looking for the data we need until we realize what the mistake might have been. And all this without really bringing any benefit, so they are tasks that must be tried to avoid as much as possible.
There are two solutions to this. One is to let the tools that work on monitoring take care of this classification. According to the data received, these tools should be able to classify the stops according to the corresponding error, even mark them as microstoppages. However, this data is not always sufficient to classify them. To solve this, the second solution comes into play.
This solution is that the classification of the stops is done by the employees who are working with the machines. This has the advantage of being less abstract, i.e. the employees rely on what they see for this sorting, so it offers much more flexibility for this sorting.
As you can see, these two solutions can complement each other, which offers a very high power for this classification. Since errors would be automatically classified and, in case of being wrong, could be reclassified. In addition, when an alert is classified, the necessary warnings will be automatically made so that it can be solved.
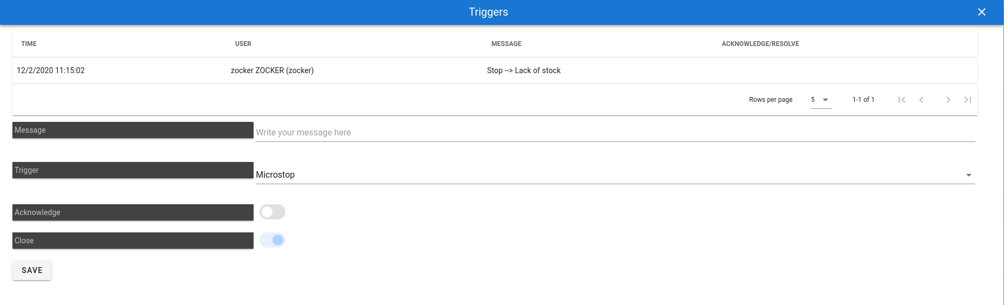
It is also very important that the classification of the alerts is done in a simple way, to avoid wasting time and errors. It is also important to be able to indicate if the errors are solved or in the process of being solved, as well as to leave some indication. With our platform it can be easily done:
There are two solutions to this. One is to let the tools that work on monitoring take care of this classification. According to the data received, these tools should be able to classify the stops according to the corresponding error, even mark them as microstoppages. However, this data is not always sufficient to classify them. To solve this, the second solution comes into play.
This solution is that the classification of the stops is done by the employees who are working with the machines. This has the advantage of being less abstract, i.e. the employees rely on what they see for this sorting, so it offers much more flexibility for this sorting.
As you can see, these two solutions can complement each other, which offers a very high power for this classification. Since errors would be automatically classified and, in case of being wrong, could be reclassified. In addition, when an alert is classified, the necessary warnings will be automatically made so that it can be solved.
It is also very important that the classification of the alerts is done in a simple way, to avoid wasting time and errors. It is also important to be able to indicate if the errors are solved or in the process of being solved, as well as to leave some indication. With our platform it can be easily done:
Importance of display
Parallel to a correct classification of these errors and just as important, is the display of them. In the previous section we saw how the errors were shown in a list, which can be a good system to visualize them, but which is not capable of giving us all the necessary data so that complementary representations would be needed.One of these complementary representations could be an operating bar, useful if we want to see how long it was stopped in relation to the operating time. It would look like this:

You can also take advantage of the classification made previously to show the errors in this same graph, being as follows:

However, this representation is still a bit incomplete, as there are several important data that should be represented and do not, as they are important, such as a count of the number of times an error occurs or the total time it takes. To represent these data, it is best to use a graph as a complement:

All these representations can be combined in one place or in several, depending on what we want to represent in each case. But it is important to offer several ways to visualize the data so that you can always choose the most beneficial one according to the data you want to visualize. Our platform can help with that!
In addition to the above, a good representation of these data is also necessary so that they can be easily exploited and generate a much greater functional utility than the data alone. Having very good data but not being able to represent it in a useful way is the same as not having this data, since it cannot be used by the person who visualizes it.
Conclusions
Having good monitoring is key to the proper functioning of a factory, but there are unforeseen things that also require specific treatment. For this it is necessary to use tools on this monitoring that allow us to obtain an added value, which is the differentiating mark with other companies that only have monitoring.In addition to the above, a good representation of these data is also necessary so that they can be easily exploited and generate a much greater functional utility than the data alone. Having very good data but not being able to represent it in a useful way is the same as not having this data, since it cannot be used by the person who visualizes it.

CTO & TECHNICAL DIRECTOR
Expert in industrial monitoring and data analytics.
We tell you how to improve decision-making and production efficiency in your plant, without wasting time generating reports. Your plant at a glance!
Subscribe to our Newsletter




{kind=link}
{kind=link}
{kind=link}
{kind=link}